At the beginning of the year, my only resolution was to review the past month and set some focuses, themes, and goals according to where my life was at that point. Hopefully as a way to try to avoid the pitfalls of all or nothing boolean resolutions. Consider this a trial into having a semi-public semi-regular monthly review.
The goal I set for January was to recover my fitness and get back to my pre-Christmas weight. Fortunately, as of this morning, not only am I sub-pre-Christmas, but my weight hit the goal I set back at the beginning of August when I started this journey. I have a couple of potential blog posts around the past 6 months and how I got to here – joining a running club, slow-carb-dieting – but they deserve some time and thought to themselves.
It’s not a direct goal or aim, but I need to figure out where to go next. I’ve never got to my goal weight before – when I’ve lost significant weight previously, it’s been until “that’ll do” and then it’s gradually (or sometimes quickly) piled back on again. So my focus needs to be, what about this eating program has really worked for me, and how do I adapt that to focusing on other things like fitness, strength, and not necessarily a calorie deficit? This is something I will think about over the next week, and in the meantime, I’m going to keep “slow-carbing” – if only because I have a leg injury right now and am running minimum mileage.
With that goal in mind, throughout the last month, fitness has been my main non-work focus. I’ve run in a couple of cross country events, and started to see some gains in my speed.
Outside of fitness, I made some decent progress on my playground project, without doing much more than fiddling with code while I watched TV. I did a bit of CSS tidying up – although that’s something I’m hoping to revisit after I have a calendar-like visualisation implemented (which might be a month or two away). It looks horrible, almost as if I’ve just mashed a bunch of styling together without much thought. Mad that 👀.
I got generic WordPress pages loading in, which allowed me to initially bring my /now page across – so I can not keep that up to date in two places, rather than one.
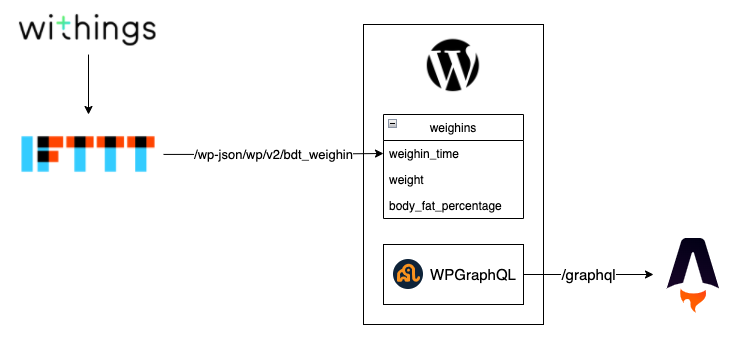
I think that most significantly, I got podcast integration working. I’m really pleased with this, it’s a set of data that I can’t look at at a glance anywhere else. It also might serve as a jumping-off point if I ever want to write anything about the stuff that I’m consuming day-to-day. I have a bunch of Permanent Notes in my Zettelkasten that start off as Fleeting Notes from podcasts, maybe there’s something I can do here to make some of that process public?
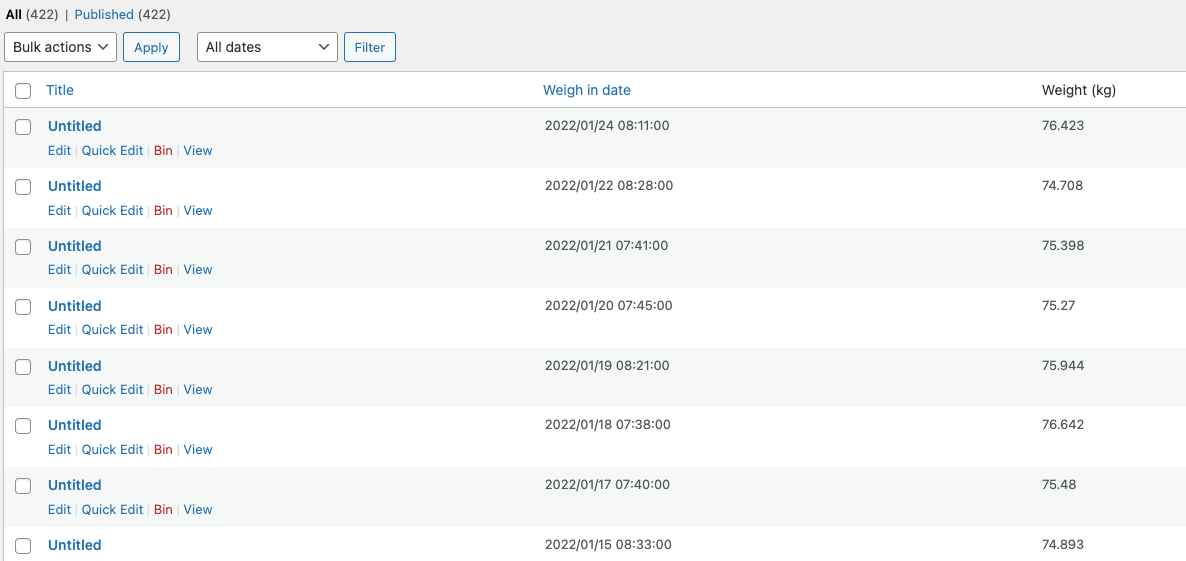
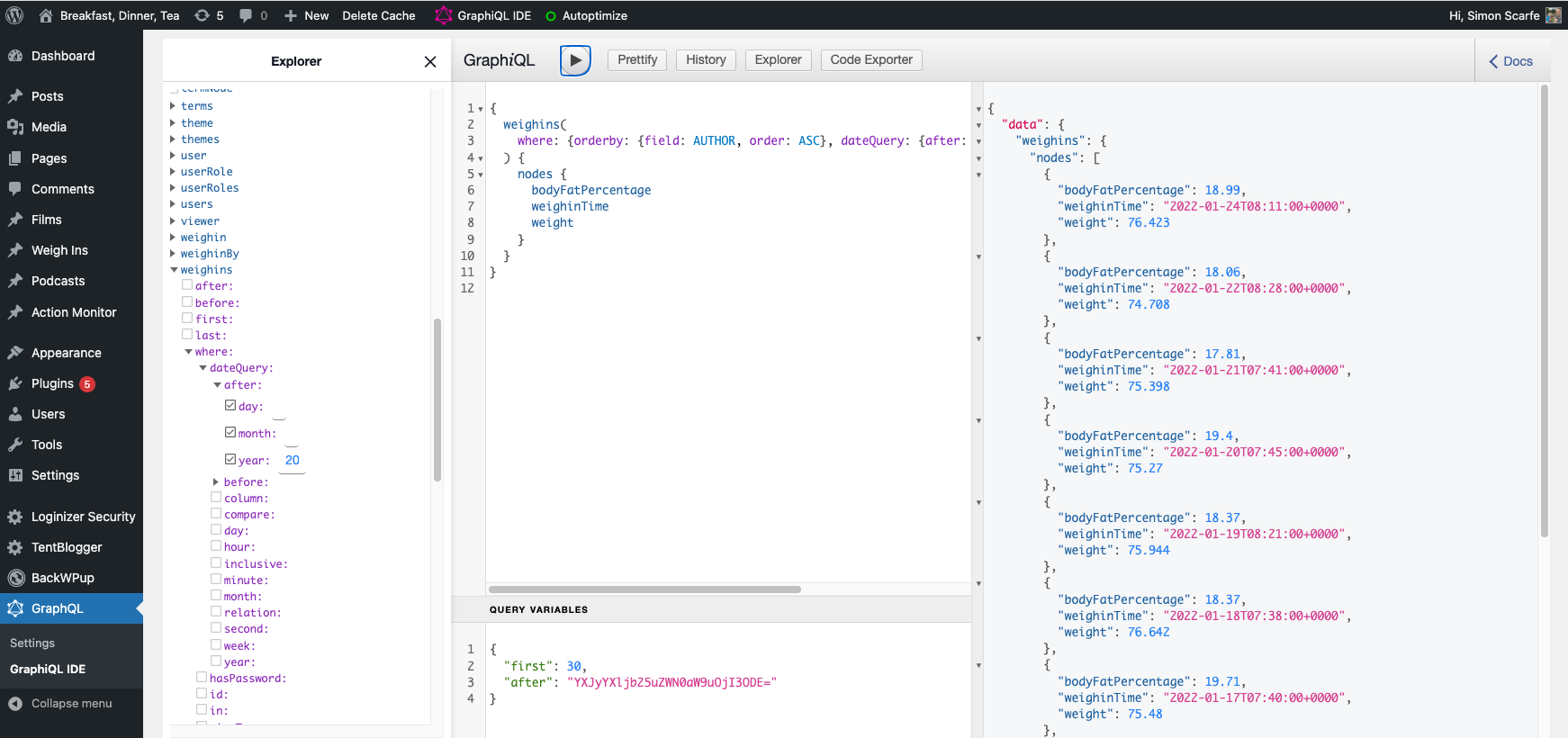
And I started in earnest doing something with my Weight data. There’s a bit of a spike over at https://playground.breakfastdinnertea.co.uk/weight/, but that might change significantly in the next week or two. I might even pivot libraries, given my experience with Nivo so far.
February
Next month, there are a few things I wish to focus on:
- I want to write more. Not necessarily on here, but rather in Roam (or maybe DayOne, depending on what’s more natural) – whether that’s free journaling, morning pages, or something else. I know that if I want to write better, I need to write more. I also want to do more reflecting on what I’m doing to take stock a little and figure out whether I’m just doing stuff for the sake of doing it.
- I want to lock down an approach to pivoting my diet and fitness regime to something more long-term sustainable and runner-friendly. I have something in my head around this, but I need to better formalise it – it’s a combination of things that work for me across Slow Carb, Intuitive Eating, and Racing Weight. But I guess I have to play with it and see if it meets my longer-term goals (improve running performance, don’t put weight back on, maybe lean up along the way), and whether it is sustainable as a set of life-long habits.
- Finally, don’t let my ego get the best of me, and fully recover from this injury, even if it means my weekly mileage suffers temporarily.
Consumption highlights
Films
Not a massive movie month, but saw some corkers.
TV
I caught quite a bit of good TV this month. Yellowjackets was by far my favourite. Our lunchtime light binge has been Mortimer and Whitehouse: Gone Fishing, which I’m now sad to have finished.
Podcasts
- This week, one of my favourite podcasts, The Tip Off which covers stories of fascinating and important investigative journalism cases, returned. This one covers slave labour in the British building industry, it is a great listen.
- One from back in July, but I listened to a fascinating interview with UK Ultrarunner, Damian Hall on the Strength Running podcast – great listen, all about the dangers of drinking too much water and his experiences running stupidly long distances.
- If you’ve not caught one yet, you should give Blindboy’s podcast a listen. His “hot takes” are amazing, I would love to see his process for putting this stuff together, because they go all over the place, make a billion great points, and then always seem to resolve to a nice take-home message full of nuance and humanity. I listened to one about pineapples in Ireland this month, and it didn’t disappoint.
Books
- This month saw me finally complete Staff Engineer: Leadership Beyond the Management Track – a book that I finished the meat of earlier in the year, but I trickled the interview section as and when I had the breadth. Well worth a read for anyone wanting to know what a software engineer might do beyond senior. (Without spoiling much, it is one of a billion things).
- I’ve also progressed and nearly finished Team Topologies, which is full of pragmatic wisdom about how to create teams that foster both autonomy and alignment. And in fictionland, I’ve been really enjoying A Wizard of Earthsea, one of those many “classics” that I’m only now getting around to.