My playground project started from a Google Sheet I found on Reddit to track my weight. I initially only wanted to play about and create some visualisations for it. But,eventually I stopped using that spreadsheet and, like most of my weight-loss escapades, got fat again. In the meantime, the playground developed into a hodgepodge of data sources. There was little rhyme or reason to a lot of it but kept me busy and off the streets.
Since then, I bought myself a fancy Withings body fat scale and have continued to track my weight with that. It does a job, but I don’t like that it locks me into Withings’ platform forever. One day it might shut down – leaving me at best with the hope that they’ll make my data available as a half-arsed CSV file.
I also missed some of the features in the original weight tracker. For instance, I implemented rolling average graphs. These give an idea of how my weight is trending over time, rather than day-to-day fluctuations. As much as I care about how big the poo I did was that day, the average is much more useful.
So I set to extract that weight to my own data store of choice, WordPress. It is not the first place I’d visit for storing time-series data that I could later display as graphs. Or to create an Event store to create my own personal audit trail. It is also not what I would consider a “sexy” technology choice. The primary APIs are all in PHP, a language I’ve not written in any significant manner since 2015. But it’s free, open-source, has a huge vault of useful plugins, and is malleable.
The querying/visualisation is still a work in progress. You can see how it’s going at this top-secret, hard to guess URL: https://playground.breakfastdinnertea.co.uk/weight/. With that said, the main method of data ingress has been up and running for well over 6 months now. It feels stable enough to talk about.
I was recently sharing this with a new Slack that I’ve joined (Si Jobling‘s On The Side slack). Si asked me about this particular integration, which I’ve taken as a prompt to make me write some of this down. If only so that when it next breaks, I have a little dummies guide to help me debug it all.
Overview
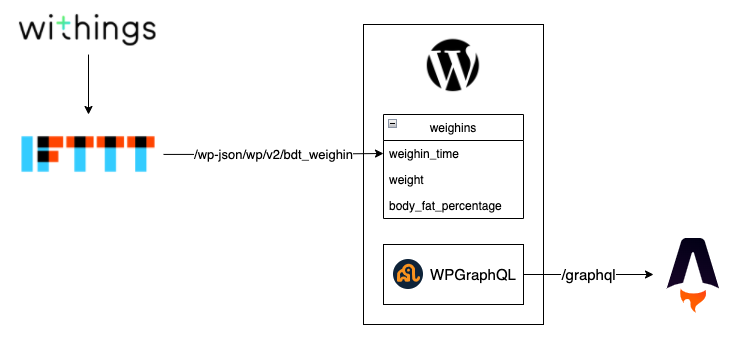
Here’s a bit of a dodgy and incomplete diagram showing what the information flow looks like. The “A” logo at the right is for the fantastic Astro framework which I use to render the playground. It is very early in its development, but a lot of fun to use. I’d encourage you to give it a look over if that’s your bag.
I won’t go into too much detail on the rendering part, if only because it’s still early days. But the rest of it, I’ll dig into a little below.
Custom Post Types
WordPress allows you to create your own data types using Custom Post Types. There are plugins to define these, but I like having the control you get from setting them yourself. Also, the custom post types API is dead simple. Custom types are exposable using WPGraphQL. Which gives the added bonus of not worrying about a domino chain of dependencies being up to date.
It registers the 3 main fields in that custom post type. The “sanitize_callback” property allows you to translate from Withings format to something UTC-like.
WPGraphQL
GraphQL allows me to export those post types for consumption off-site. From there, I can aggregate and filter data without having to write custom business logic. I didn’t choose GraphQL from the outset. I started using it because I was integrating against Gatsby, where the primary API is GraphQL. Fortunately, it’s a common interchange method, so I have stuck with it.
WPGraphQL is a plugin that allows you to expose data in your blog as a GraphQL schema. Once installed, it provides a single endpoint from which I can query for lots of different data at once. For simple integrations like a single feed of weights, this is likely overkill. But here it presents new interesting opportunities. I could one day, for example, create a no-extra-code FriendFeed-like aggregation. Because no, I still haven’t realised it’s not 2008 anymore.
It is a bit repetitive, but it allows me to tune the schema and set up some of the fields I want to filter and sort by. It also gives me extra resilience – I can keep the APIs inline myself, instead of being at the mercy of plugin authors staying up to date with each other. This generally isn’t a problem, but I have seen instances where one plugin in a dependency chain updates before the others follow. This has created some dead hard to debug problems, sometimes only solvable by pinning to specific plugin versions.
WordPress JSON Rest API
I don’t know how well known it is, but WordPress has an incredible REST API. Seriously, a really good API. Without doing anything special, once you’ve turned it on, you can post into it (and read from it, if you’re a traditionalist) and it will act on those posts as if you were entering data into its admin interface. The only problem you need to solve is authentication. There are a billion plugins for this – from OAuth2 through to basic HTTP. You should only use basic HTTP if you’re comfortable giving a third party service your username and password. (You should not be comfortable doing that, btw).
I use the fantastic IndieAuth plugin – it’s a bit of a hangover from when I integrated everything with the IndieWeb suite.I ultimately stepped away from that suite because all my customisations broke anytime the plugins updated. I should probably switch out to the OAuth2 plugin at some point, but this works for me as it stands. You generate a token with a scope of what it can do in your WP instance, and then use that token anytime you need to use a privilege.
IFTTT
IFTTT is a nice little service that pipes data between lots of different APIs. It has connectors for both Withings and WordPress, although the WordPress one only covers basic post types. So I make heavy use of its “Make A Web Request” connector.
A previous iteration of this web connector sent a request to a relay lambda I created to pass through the access token. But at the end of last year, IFTTT added the ability to create custom headers to your web requests. This means I can now retire that relay. I enjoy deleting code.
I have that hooked up to the Withings connector. And now, any time I weigh in, data starts trickling into WordPress.
And that’s pretty much it
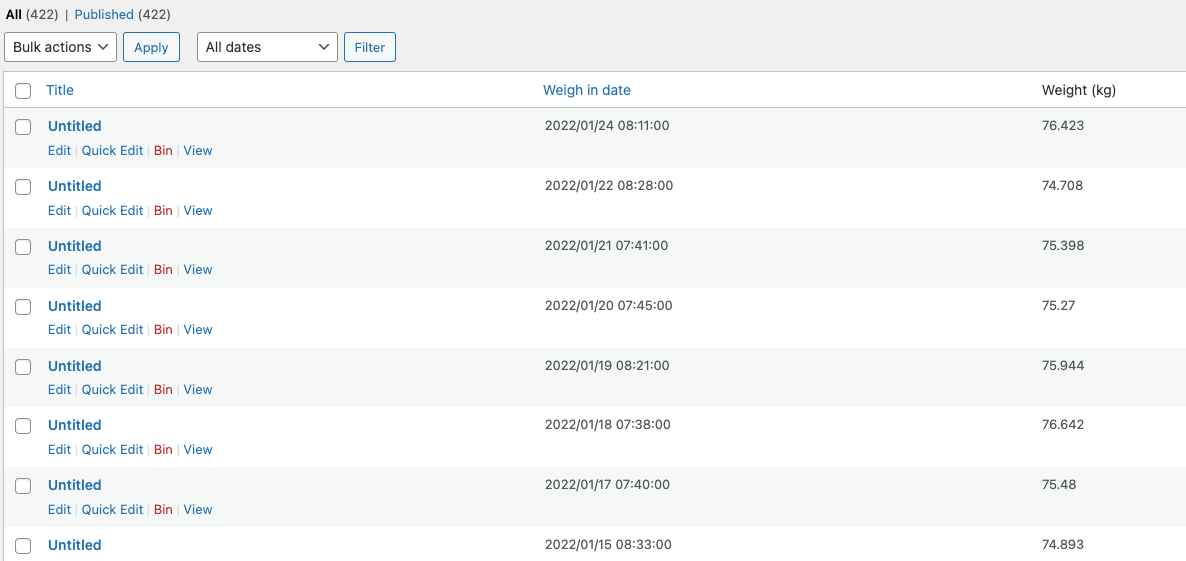
At this point, I have a database slowly filling up with my weigh-ins from Withings:
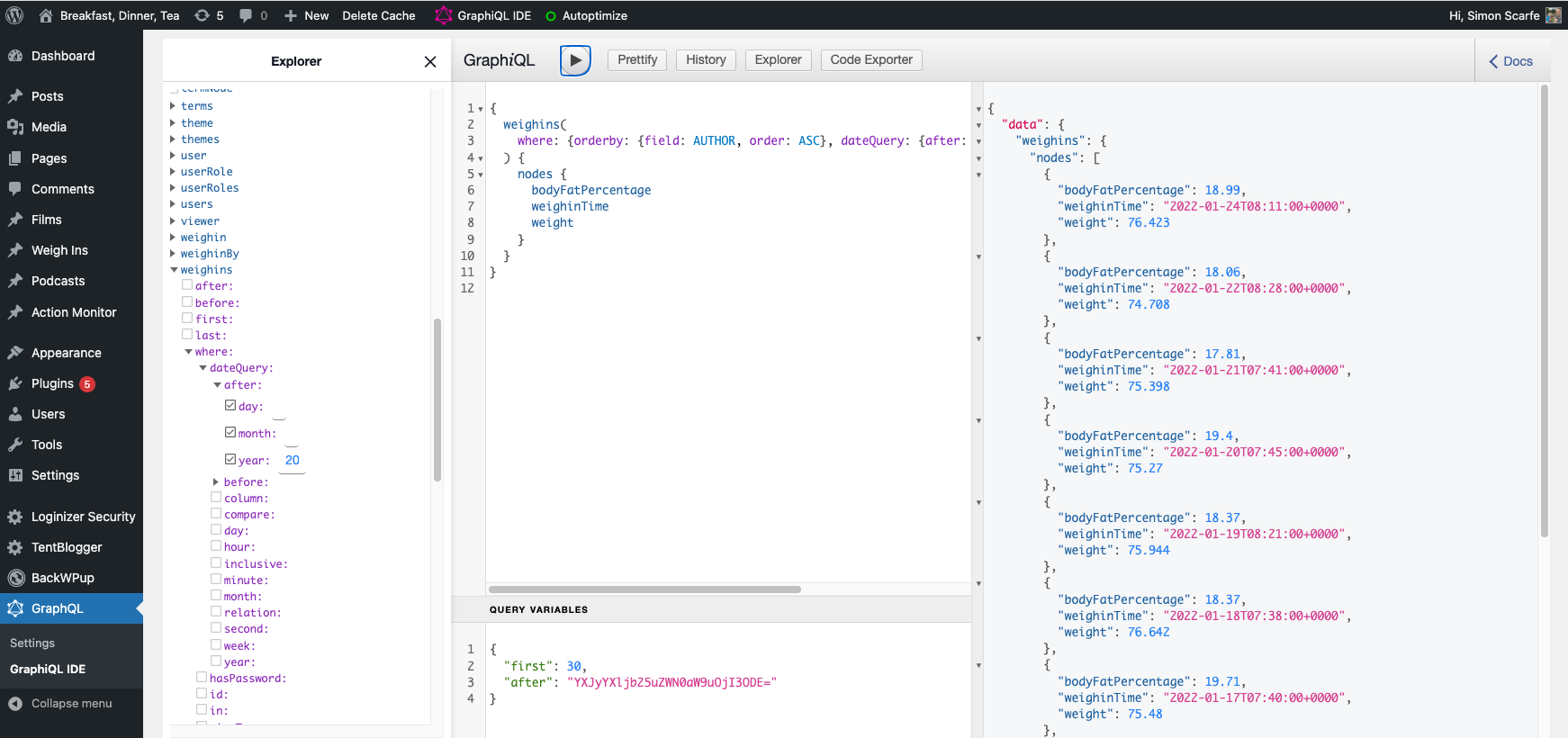
It’s far from pretty, but it works. There is a TODO somewhere to fix that “Untitled” link. And it’s also queryable from GraphQL, in a much more digestible format:
Admittedly, this a fair bit of messing on, and it is absolutely too much work to justify a single content type. But I now have films, podcasts, and weigh-ins wired up and I intend to pull in more. I’m hoping that the benefits multiply as I add more stuff. But even if they don’t, the worst-case scenario is that I have a nice PESOS style backup for when services either shut down or arbitrarily kick me off.
And with that cheery thought, thanks very much for reading this far. I hope it is of some use to someone out there. If you want to dig into the implementation, it’s poorly documented but available in my mini-repo. Some pointers of where to look:
A while back, I documented a silly approach to trying to keep, erm, tabs on the way I use Firefox.
This worked pretty well until I decided to have a play with Vivaldi, a power-user focussed browser based on Chromium. I ended up ripping out that functionality from my dotfiles.
This evening I realised I still have the same problem, so had a go at reimplementing it for my new browser, to discover that it’s far simpler now without having to hack around with Firefox’s massive saved session file.
Since I wrote that post, someone else has looked into taking the idea to the next level and graphing it all in grafana. Something that when I find some spare time, I might look at replicating (although I’m sure my solution will be far less elegant).
Awesome humanistic approach to RFCs from Tanya Reilly – moving from binary “computer says no”s to a more iterative process by changing some simple wording.
Recently, I posted on here about using Hammerspoon to scratch a personal itch. It was a nice exercise in documenting stuff for myself while hopefully putting something out into the ether that might be of use to others. So I thought I’d try it again.
The problem
During the summer, I started using Roam Research for all of my note-taking and personal knowledge management. You don’t need me to tell you why you should or shouldn’t be using it, there are enough of us out there already proselytising about this thing. But the long and the short of it is that absolutely everything I come across and think about is going in there – personal stuff, work stuff, little snippets of data that might one day be useful to me again. It has become a vital tool in my day-to-day thinking and planning.
One of the templates I’ve been using to take personal notes for meetings looks like this:
I find this fantastically useful, the “Attendees” section is particularly good for some of the natural cross-referencing it provides. But when you have a day of six or more meetings, filling in those can be tiresome, to the point where I actively avoid doing it (even with TextExpander shortcuts). When this happens, I both lose the value it provides, and I feel like a bit of a failure – which is never nice.
The solution
I decided to see if I could script exporting those meetings to markdown – trying to turn what is a bit of a laboured, several-times-a-day process into a simpler, single keyboard shortcut. And without wanting to spoil too much, it turns out I could. Not only that, but it was pretty straightforward.
I started out by using MacOS’s Script Editor to hack around the Outlook API so I could see what I might query on. When researching this, I found several pages about getting information using the frankly-quite-weird AppleScript language, but very few using Apple’s JavaScript for Automation extensions (JXA). After about 20 minutes of screwing around, most of what I required could be retrieved using Application("Microsoft Outlook").selectedObjects() (seriously). The trick to enable this is to activate Outlook Calendar’s “list view” (CMD+CTRL+0), so you can select several meetings without triggering extra UI elements.
Once I’d accessed those events, I turned them into plain ol’ JSON with the intention of letting Hammerspoon deal with them – before realising that Lua is not a strength of mine – so I continued using JavaScript to transform those objects into Roam-compatible markdown. You might wonder how bad Lua not being “a strength of mine” could possibly be by looking at the digital “chicken scrawl” that is the chained JavaScript I assembled to do that here.
Finally, it was a matter of hooking it all into Hammerspoon. Hammerspoon provides hs.osascript.javascript to execute JavaScript, hs.pasteboard.setContents to copy the results of that JS to the clipboard, and hs.hotkey.bind to hook it all up to a keyboard shortcut. I’ve probably overused the sentence a bit in this post, but it was all rather straightforward. Honestly, look.
Limitations
This isn’t without some slight flaws, the biggest one is Roam’s (or maybe it’s MacOS’s?) treatments of soft line breaks. I couldn’t find a way in Roam to paste in soft breaks, which leads to agendas pasting in as multiple blocks. That may be less problematic for more traditional outliners, but a lot of Roam’s power comes from blocks being first-class citizens that stand on their own. To get around this, in the short term I replaced them with `------` text, which I can quickly edit around if/when I find it appropriate. Fortunately, most agendas are a bit rubbish, and I only need a couple of lines of a LOT of (usually Zoom-related) bumph.
Also, none of this has been tested on “New” Outlook 365. I am a bit worried that if I upgrade (forced or otherwise), this functionality will quickly disappear. Maybe then I’ll finally start using a more portable/flexible email/calendar client?
And on a similar theme, as I have been reading around Applescript / JXA, those technologies might not be in Apple’s long term plans. That the information on how to do all of this was hard to find, could probably be taken as a symptom of this. However, if you are interested in digging more into JXA, the JXA Cookbook is a decent starting point
But all of that aside, once I’d got my head around the JS/Applescript nastiness and weird Osascript APIs, it was a pretty simple experience. Even if it all went away tomorrow, I’ve likely already saved some serious time manually adding people’s names to [[Meeting/]] posts.
Chris Ferdinandi has thrown in some absolute gems in this talk he put together for wordpress.tv – The Lean Web, well worth 48 minutes (or less at > 1x) of your time.
I originally gave this book 3/5 on Goodreads, however, now I’ve revisited the book and made some personal summarisations from my highlights – I feel I need to revisit that.
My original just-finished-it instinct was that the research part of the book was too deep and took me into methodologies that I ultimately don’t care about. In fact, I nearly dropped out during that section. Having battled through, I realise that would have been a mistake – after that, there is a great leadership case study that really hits home some of the messages around the culture the book promotes needing to be developed and learned, rather than being the result of blindly applying archetypes.
Still, the research methodology part is a third of the book – at least structurally. I would advise any potential readers that that is entirely skippable if you’re prepared to trust the source and take the advice it’s pushing at face value. After all, the advice is backed with logic and reasoning – which for me, is more persuasive than “we spotted correlation in these heuristics for high performing organisations”, which isn’t as compelling for me as it may be for others.
The first part of the book is full of absolute gold, end to end. Mostly backing up a lot of the literature around the benefits of things like Continuous Delivery, Lean Product Management and working in agile teams. But it presents it in a nicely joined-up way, built around the hypothesis that high performing teams deliver quickly and build stable systems – offering four simple heuristics that theoretically cement those two features.
It digs a lot into building organisational cultures – citing some of the good research into what makes for a performing team at Google (Westrum generative cultures, learning organisations, etc).
It examines technical practices that contribute to the above – why and how continuous delivery works, the benefits of automation, versioning everything, test strategies, embedded disciplines (devops, devsecops, the job of testers in a highly automated world etc).
There’s large importance put on security, reserving a full section to it – where the conclusion (naturally, given some of the authors’ previous DevOps literature) is that you should build it into your process as early as possible.
I found the culture and leadership sections to be particularly good – backing up a lot of my own personal thoughts and biases. Lots about organisations forming their own paths and not just mimicking their way to culture change – which feels obvious, but probably isn’t given how much Cargo Cultism there is in tech.
I think that all in, there aren’t any new conclusions drawn in this book, but it is great to have them in one place. The book sees its own USP as the exhaustive research, but as I say, I found it exhausting, and not to be its real strength. The density and jumping off points & onward knowledge journeys are what really made it a great read for me.
My current favourite thing is screencasts with hilariously over the top soundtracks. Never has writing a netlify function in Vim and deploying a hello world endpoint seemed so cool.