Update – 12/11/2021: A while back I switched to a Chromium-based browser, I’ve documented the new approach here.
My Problem
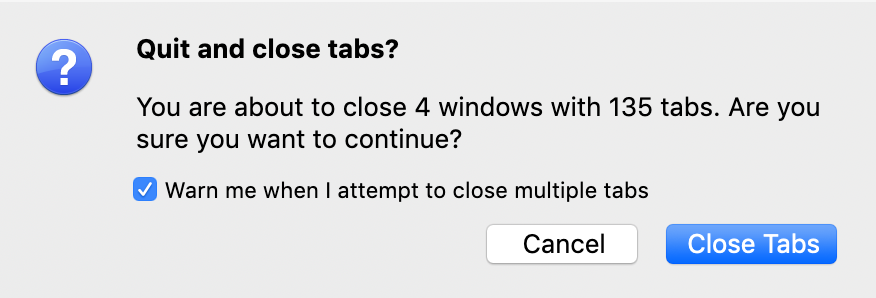
Everyone I work with at some point mentions my browser tab mismanagement. As of right now, I have 135 tabs open, but that’s definitely at the lower bounds of where I am typically at.
For years I suffered under of Chrome’s tab Toblerone of death (“Tablerone”?), which constantly reminded me of my dysfunction with only an icon to identify which tab was which.
Recently, I started using Firefox again and it enabled my problem by presenting my open tabs in a carousel UI. So it wasn’t until my Mac told me I had no memory left that I realised how bad it had got.
The carousel obfuscates the exact number of tabs I have open – leaving the quickest (and only obvious) way to find out in Firefox through hitting CMD+Q – which triggers the above dialogue.
It may sound like this is kind of a weird brag, but it’s not. This problem isn’t one I’m delighted with having. My open tabs present a combination of lackadaisicalness (in that sometimes I just plain forget to quit out of them) and flawed aspiration (“I’ll get to reading that imminently”). By the time I get to declaring tab-bankruptcy and bookmarking them (using a combination of the OneTab extension and Pinboard ), they’ve amassed to a point where I sometimes no longer know why they’re there.
The Tool
Yes, I obviously have a problem. And once I’d admitted it, I started looking into ways to manage it. My chosen approach would be to better surface the above number, so at least it would become more quickly apparent that I’d gone too far.
I don’t want to move away from Firefox, and I don’t want to have to threaten to quit anytime that I want an update on my tab count. Nothing obvious was coming up in my searches until a little later I was pursuing another itch (hyper customisable window management, if that matters) where I stumbled upon some articles about a tool called Mjolnir, which had been forked to a more batteries-included tool called Hammerspoon.
The Hammerspoon splash page does a better job of describing it, but the tl;dr is it adds a scripting layer to MacOS using Lua. This seemed powerful enough for me to craft something that might suit my needs here.
Crafting A Solution
So with my hammer in hand, I needed to craft a way to address my “issue”. I’m a big fan of “Quantified Self“, and Continuous Improvement – both philosophies that involve surfacing and using data about yourself to improve a situation. So I figured – if that number is always in my face, shouldn’t I naturally try to optimise it now and again?
With that question in mind, I started looking at the Hammerspoon API, and initially, I figured this would be easy. Hammerspoon surfaces a method on a Window called tabCount, so this should be incredibly easy to integrate. Unfortunately not – the data it returns in Firefox isn’t representative of how many tabs you have open. At a guess, I expect Firefox isn’t using a native macOS tab implementation, and so this was an immediate dead end.
Then I started looking at methods in Firefox for surfacing this number. I’m sure I could automate a brute force counter somehow, but I don’t know how I might implement that in the background without interrupting the user. Firefox tracks “telemetry” for reporting browser usage. I found that stuff dead interesting, I’d encourage you to give it a read (all of the data is viewable in your instance at about:telemetry).
However, the only relevant number I’ve found is `browser.engagement.max_concurrent_tab_count`, and that only reflects the maximum number of tabs you’ve opened in that session. Which isn’t great when you’re trying to get that number down. Also, it doesn’t seem simple to query that data – you can get all sorts from FF’s SQLite databases, but I never landed on this value.
After lots of faffing, I finally discovered the session restore file found in your Firefox Profile directory at `sessionstore-backups/recovery.jsonlz4`. It’s the file that Firefox uses to restore your session when it runs out of memory because you’re an idiot who had too many tabs open. The file is massive – particularly if you have large amounts of tabs open – and in a slightly arcane format – lz4 – which on reading, you’ll see is a suitable compression format for the problem at hand. I expected that if we can parse that file quickly, it should be suitable for the job we have here – reporting regularly on the current number of tabs open.
Implementing a Firefox Tab Counter in Hammerspoon
First of all, I needed a fast way of reading that file. After some digging and pissing on with weird different libraries, I managed to get a fork of lz4json compiling locally – not only did it work, but it was fast: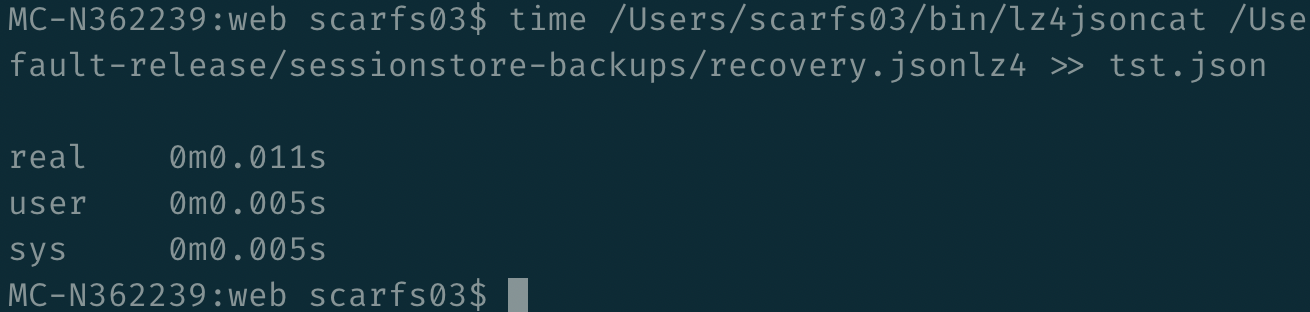 Then I needed to parse it. Instinct got me going down the “I’ll write some javascript for this” path, but I quickly realised that for fast feedback, I needed something close to the metal, simple, and again fast. So I dived into what describes itself as “sed for JSON data”, jq, and realised that this type of problem was its bread and butter.
Then I needed to parse it. Instinct got me going down the “I’ll write some javascript for this” path, but I quickly realised that for fast feedback, I needed something close to the metal, simple, and again fast. So I dived into what describes itself as “sed for JSON data”, jq, and realised that this type of problem was its bread and butter.
Piping the above catted file into this strange incantation:
| jq 'reduce (.windows[] .tabs | length) as $length (0; . + $length)'
gives you a value that matches up exactly with the dialog box we get when hitting CMD+Q. Woop!
To try and explain the above, `.windows[] .tabs` gives you an array of tabs in each window. `| length` gives you the result of the length method applied to that array. And reduce applies a reduce operation to each of those windows, in our case adding them to get a total amount of tabs open.
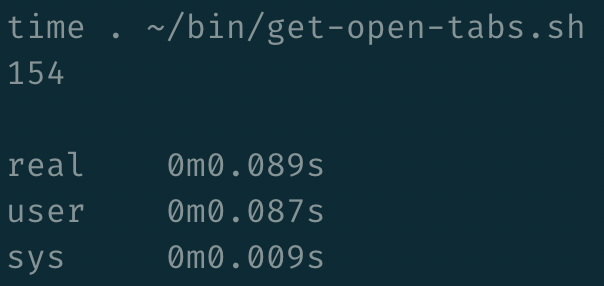
Combine all of that into a little shell script, and by applying our ultra scientific `time` method of measuring the speed of it all, we still get sub-tenth of a second times:
That strikes me as a fast and feasible way of retrieving a tab count. So next step – surfacing it somewhere obvious. Working through the Hammerspoon getting started guide, you quickly come to a tutorial around simulating Caffeine in the menubar. This was incredibly straightforward and seemed like a nice obvious first step for getting stuff somewhere. So that’s what I did – we run the get open tabs script, and put the result of that in the menubar, using Hammerspoon’s PathWatcher utility to update that number whenever our session restore file changes.
I added a couple of enhancements, but nothing hugely complex – a limit constant that turns our number red when our open tabs are greater than it (at time of writing, I’ve exceeded it by 70 😬). And I had a play with creating an icon, which was incredibly straight forward. It’s based on this “format” (if you can call it that), which is self-documenting enough that I figured it out from looking at a couple of other instances of icons.
The script itself currently lives in my dotfiles, and I’d be happy to help anyone else trying to do something similar if they get stuck trying to replicate any of this. When it all comes together, my menubar looks a little bit like this:

Which is everything I had hoped for. Has it fixed my problem? Goodness me, no. But it has been a fun learning exercise, and it makes me think twice before randomly middle-clicking links.
